- wgetとはソフトウェア(ダウンローダー)
- wgetの特徴
- wgetコマンドを使うためにHomebrewをインストール
- wgetを使う前に注意する事
- wgetの使い方
- wgetを使って単一のファイルをダウンロードする
wgetとは
wget(正式名称:GNU Wget)とは、HTTP,FTP通信を使ってサーバーからファイルやコンテンツをダウンロードするためのソフトウェア(ダウンローダー)です。wgetをインストールすればコマンドラインから簡単に使えるようになります。
wgetの特徴
wgetの特徴としてクローリング機能(複数のファイルを一度にダウンロードしたりwebページのリンクを辿って複数のコンテンツをダウンロードしたりできる)
wgetコマンドを使うためにHomebrewをインストール
Homebrewは各自の環境に合わせてダウンロードしてください。
Homebrewをインストールできるとbrewコマンドが使えるようになります。
$ brew --version
3.5.9続いてWgetをインストールします。
$ brew update #Homebrewパッケージ自体とインストール可能なソフトウェアのリストを更新する。
$ brew install wgetインストールできるとwgetコマンドが使えるようになります。
$ wget --version
GNU Wget 1.20.3 built on darwin19.0.0↑のように各々のバージョンが表示されたら成功です。
wgetを使う前に注意する事
wgetは適切な間隔を空けて使用しないと相手側のサーバーに負担をかけてしまいます。
過去には脆弱なサーバーにリクエストを何回も短時間の間に送って1秒間に一回程度のアクセスでもサーバーがダウンして事件になったこともあるので、robots.txtというページ(クローラーなどに対するアクセスルールが書いてある)を確認して必ず余裕を持った間隔で実行しましょう。
wgetを実行する前に対象URLに/robots.txtという言葉をくっつけて対象先がどう設定しているか見ておきます。
例えばyahooのクローラー対策はどのようになっているのか見てみましょう。
https://www.yahoo.co.jp/robots.txt
そうすると、robots.txtのページが出てきました。
User-agent: * と出てきました。User-agentはユーザーの代わりに巡回するプログラムの事でクローラーなどを指します。 この場合、User-agent: *となっているので、巡回していいよ!という意味になります。逆にGoogleなどだと厳しく制限されていますので、ご注意ください。
詳しくはここのページを参照してください。
例えばワードプレスなどのrobots.txtは
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://ドメイン/wp-sitemap.xml となっていたりします。 ロボットのクロールはOK. 管理者ページのクロールは禁止.
wgetの使い方
一つのファイルだけダウンロードしたいならwget単体でも使えますが、オプションを組み合わせることで自由度の高いクローリングが出来るようになります。
| オプション | 説明 |
| -V,--version | Wgetのバージョンを表示する。 |
| -h,--help | ヘルプを表示する。 |
| -q,--quiet | 進捗状況などを表示しない |
| -o file,--output-document=file | fileに保存する。 |
| -c,--continue | 前回の続きからファイルのダウンロードを再開する。 |
| -r,--recursive | リンクを辿って再帰的にダウンロードする。 |
| -l depth,--level=depth | 再帰的にダウンロードするときにリンクを辿る深さをdepthに制限する。 |
| -w seconds,--wait=seconds | 再帰的にダウンロードするときにダウンロード間隔をseconds秒空ける。 |
| -np,--no-parent | 再帰的にダウンロードするときに親ディレクトリをクロールしない。 |
| -I list,--include list | 再帰的にダウンロードするときにlistに含まれるディレクトリのみを辿る。 |
| -N,--timestamping | ファイルが更新されているときのみダウンロードする。 |
| -m,--mirror | ミラーリング用のオプションを有効化する。 -r ,-N ,-l ,inf ,--no-remove-listingに相当。 --no-remove-listingはFTP通信でのみ有効な.listingファイルを消さないためのオプション。 |
wgetを使って単一のファイルをダウンロードする
ここから実際にファイルをダウンロードするコマンドを書いていきます。まずは
単一のファイルをダウンロードの仕方です。
$ wget https://任意のドメイン/リンクを指定していき、深い階層のファイルも同様に取得することができます。
$ wget https://任意のドメイン/一階層深いディレクトリ/一階層深いディレクトリ/○○○.jpg例えば指定したjpeg画像をダウンロードするような場合は↑のように指定することでダウンロードできます。でもこれでは、あらかじめその階層まで知っていないと↑のようには書けません。
オプションを使って再帰的にクローリングしてみる
Wgetでリンクを辿ってクローリングするには、-rオプションを使って再帰的にダウンロードすることができます。
例
$ wget -r -np -w 10 -l 1 --restrict-file-names=nocontrol https://任意のドメイン/↑のコマンドの場合、どういった動きをするクローラーになるかというと、
任意のドメインをリンクを辿って再帰的にダウンロードします。その際、親ディレクトリは再帰的にはクロールしません(最初だけダウンロードする)。10秒間の間隔を空けてクロールします。リンクをたどる深さは1に設定します。--restrict-file-names=nocontrolはURLに日本語が含まれる場合に、日本語のファイル名で保存することを意味します。
コマンドを実行すると、カレントディレクトリに対象URLのディレクトリが作られ、その中に次々とファイルがダウンロードされていきます。
ダウンロード完了と出たらファイルがどういう構造になっているかtreeコマンドで見ていきましょう。
$ tree 対象ドメインすると、
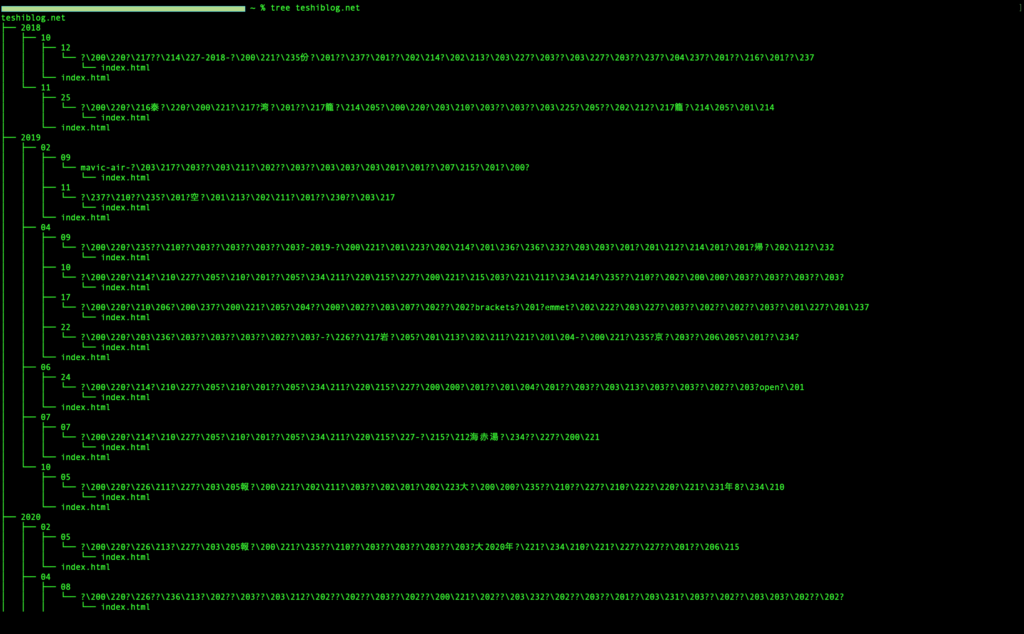
クロール間隔は最低でも相手サーバーに負荷をかけないように必ず二秒以上は空けるようにしてください。
このようなツリー構造で表示されてダウンロードされたことが分かります。
今回はこの辺で以上となります。ご覧いただきありがとうございました。